Ремонт компьютера за час на дому и офисе
Каталог статей
| Главная » Статьи » Статьи |
Глоссарий по RAID технологии
 AutoSwap (Автозамена) - функциональная замена вышедшей из строя сменной части в дисковой системе, выполняемая самой дисковой системой непосредственно без человеческого вмешательства. В это время дисковая система продолжает исполнять свою нормальную функцию (сравните с Hot Swap).
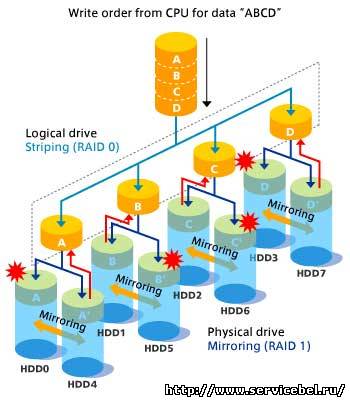
Background Initialization (Фоновая Инициализация) - процесс, при котором инициализация дискового массива идет в фоновом режиме. Использование фоновой инициализации позволяет получить доступ к дисковому массиву уже через несколько минут вместо нескольких часов. Другое название Immediate RAID Availability (Немедленная доступность RAID). BBU - Battery Backup Unit (Модуль Резервной Батареи). BBU обеспечивает батарейную защиту питания для кэша контроллера RAID. В случае сбоя питания, BBU поможет сохранить данные в кэше. BIOS - Basic Input/Output System (Основная Система Ввода - Вывода), программное обеспечение, которое определяет то, что компьютер может делать без обращения к программам. BIOS содержит весь код, требуемый, чтобы управлять клавиатурой, экраном, дисководами, последовательной связью, и другими функциями. Обычно BIOS записан в микросхеме ROM, установленной на системной плате так, чтобы BIOS всегда был доступен и не зависел от наличия / сбоя дисковода. Иногда BIOS записывается в микросхему флэш-памяти, позволяющей обновлять данные. Bridge RAID Controller (Мостовой RAID Контроллер) - SCSI устройство, занимающее один ID на SCSI шине, но через которое к SCSI шине может подключаться несколько устройств. Обычно используется для управления внешними подсистемами RAID (сравните с Внутренними PCI-подсистемами RAID -см. Internal RAID Controller). Под этим термином часто понимается внешний RAID контроллер. Burst data rate (Импульсная Скорость передачи данных) - быстродействие, которое определяет количество данных, посланных или полученных в течение одной операции (сравните с Sustained Data Transfer Rate - Потоковой скоростью передачи данных). Cache (Кэш) - внутренняя память контроллера позволяющая ускорять передачу данных к и от дисковода. Cache Flush (Сброс Кэша) - относится к операции, при которой все, не записанные блоки из Write-Back Cache (кэш с отложенной записью) записываются на рабочий дисковод. Эта операция необходима перед выключением системы. Caching (Кэширование) - сохранение данных в предопределенной области дисковода или оперативной памяти (см. Cache). Кэширование позволяет получить быстрый доступ к недавно прочитанным/записанным данным и используется для ускорения операций чтения/записи RAID систем, дисководов, компьютеров и серверов, или других периферийных устройств. Cluster (Кластер) - группа терминалов или рабочих станций, подключенных к общему серверу или группа нескольких серверов, которые совместно выполняют общую задачу и способны заменить друг друга, если одно из устройств выйдет из строя. Cold Swap (Холодная замена) - физическая замена вышедшей из строя сменной части в системе хранения данных, при которой, чтобы осуществить замену, в системе хранения данных выключается питание и требуется вмешательство оператора (сравните с Hot Swap - Горячей заменой и AutoSwap - Автозаменой). Consistency Check (Последовательная проверка) - относится к процессу, в котором проверяется целостность избыточных данных. Например, последовательная проверка "зеркалированного" дисковода позволяет удостовериться, что все данные на обоих дисководах полностью совпадают. Data Transfer Rate (Скорость передачи данных) - количество данных в единицу времени, пересылаемых через канал или шину ввода - вывода в ходе выполнения операции ввода - вывода, обычно выражаемое в Мегабайтах в секунду. Degraded Mode (Ухудшенный режим) - режим RAID, когда один из дисководов вышел из строя. Differential (Дифференциалный) - протокол, при котором информационные сигналы передаются путем изменения величины или направления тока, а не напряжения, как обычно, что уменьшает чувствительность к электрическим помехам и позволяет увеличивать скорость передачи данных и/или расстояние, на которое данные передаются. Disk Array (Дисковый Массив) - совокупность нескольких дисководов общедоступных для дисковой системы и выглядящие для операционной системы как один единый дисковод. Применение дисковых массивов, также известные как RAID, совместно со специализированным контроллером позволяет улучшить отказоустойчивость и/или повысить быстродействие. Дисковые массивы обычно используются на серверах и становятся все более популярным на рабочих компьютерах и графических станциях. Disk Failure Detection (Обнаружение неисправности дисководов) - RAID контроллер может автоматически обнаруживать повреждения SCSI дисководов. Процесс контроля основывается, среди прочего, на анализе времени выполнения команд, посланных дисководу. Если дисковод в течении определенного времени не подтверждает выполнение команды, контроллер осуществляет "сброс" дисковода и посылает команду повторно. Если команда снова не выполняется за заданное время, дисковод может быть контроллером отключен (установлен в режим "offline") и его состояние фиксируется, как "dead" ("мертвый"). Многие RAID контроллеры также контролируют ошибки четности SCSI шины и другие потенциальные проблемы. Disk Media Error Management (Система Обработки Ошибок Дисководов) - RAID контроллеры способны обрабатывать ошибки внутреннего кэша и SCSI дисководов. Если установлен кэш с ECC, контроллер исправит одиночные и зафиксирует двойные ошибки. Дисководы могут быть запрограммированы так, чтобы сообщать об ошибках, даже если это восстанавливаемые ошибки. Когда дисковод сообщает об ошибке во время чтения, контроллер считывает соответствующие данные из зеркального дисковода (RAID 1 или 0+1), или восстанавливает данные, используя информацию, хранящуюся в других блоках (RAID 3, RAID 5), и записывает данные назад на тот дисковод, который столкнулся с ошибкой. Если произошел сбой при записи, контроллер пропускает тот блок, в котором возникла ошибка, и затем записывает данные в следующий блок. Если проблема была успешно решена, то никакие сообщения об ошибках в систему не передаются. Drive Groups or Drive Packs (Группы Дисков или Дисковые Пакеты) - группа дисководов (обычно одной модели), которые логически привязаны друг другу и адресуются как единое устройство. В некоторых случаях такая группа может называться дисковым "пакетом", когда речь идет только о физических устройствах. До восьми дисководов могут быть сконфигурированы вместе как единая группа дисководов. Все физические устройства в группе дисководов должны иметь одинаковый объем, иначе от каждого из дисководов в группе будет восприниматься объем равный объему самого маленького дисковода. Полный объем группы дисководов равен объему самого маленького дисковода в группе, умноженного на число дисководов в группе. Например, если Вы имеете в пакете 4 дисковода по 400МБ каждый, и 1 дисковод 200МБ, эффективная емкость, доступная для использования - составит только 1000МБ (5x200), а не 1800МБ. Drive Traveling (Перемещение Диска) - Может произойти в процессе замены отказавшего дисковода, если дисководы окажутся на местах, отличных от тех, которые они занимали первоначально. ECC - Error Correcting Code (Код с Исправлением Ошибок) - Метод создания избыточной информации, которая может использоваться, чтобы обнаружить и исправить ошибки в сохраняемых или передаваемых данных. External RAID Controller (Внешний RAID Контроллер) - контроллер RAID, который находится в собственном (отдельном) корпусе, а не вставлен в системную плату РС или сервера. Часто внешние RAID контроллеры именуются как мостовые контроллер. Failure (Отказ, сбой) - обнаруживаемое физическое изменение в оборудовании, восстанавливаемое путем замены компонента. Fault tolerance / failure tolerance (Отказоустойчивость) - способность системы продолжать выполнять свои функции даже тогда, когда один из ее компонентов вышел из строя. Как правило, для того чтобы компьютерная система была отказоустойчива, необходима избыточность в дисководах, источниках питания, адаптерах, контроллерах и соединительных кабелях. Fibre Channel (Волоконный Канал) - технология для передачи данных между компьютерными устройствами со скоростью до 1 Гбит/с (один миллиард битов в секунду). Эта технология часто применяется для соединения серверов, чтобы совместно использовать запоминающие устройства и для соединения дисковых контроллеров и дисководов. Fibre Channel, как связной интерфейс, составляет конкуренцию SCSI и просто незаменим, когда необходимо обеспечить скоростную связь между серверами или кластерами запоминающих устройств на расстоянии в насколько километров. Для работы на расстоянии до сотен метров в Fibre Channel используется коаксиальный кабель или обычная витая пара. На более длинных расстояниях требуется стекловолоконный кабель. GAM - Global Array Manager - программный пакет фирмы Mylex, который позволяет системному администратору конфигурировать, контролировать, и управлять RAID массивом через сеть. GAM позволяет, в случае критических ситуаций, посылать сообщения администратору через электронную почту, факс, пэйджер, SNMP или запускать заданные приложения. Hot Plug ("Горячее" Подключение) - операция подключения или отключения устройства от шины, не прерывая работы других устройств, подключенных к шине. Hot Replacement of Disks / Hot Swap (Горячая Перестановка / Горячая Замена Дисководов) - замена вышедших из строя дисководов без прерывания работы системы. Если в системе используется должным образом сконфигурированный контроллер, управляющий избыточной дисковой системой, то отказ одного дисковода не приводит к прерыванию функционирования системы. В этом случае системой генерируется соответствующее сообщение для системного оператора. Через некоторое время, когда активизируется замещающий дисковод, системный оператор может удалить отказавший дисковод, установить новый дисковод, и дать контроллеру команду "восстановить" данные на новом дисководе, причем все это происходит без прерывания системных операций. Как только процесс восстановления будет закончен, контроллер вернется в защищенное от ошибок состояние. Hot Spare (Горячее резервирование) - см. Standby Replacement of Disks Hot Standby (Горячий резерв) - избыточный (запасной) компонент, который входит в состав защищенной от ошибок системы и готов к использованию, но который не используется до тех пор, пока нормально функционирует основной компонент (компоненты). Hot Swap (Горячая Замена) - процесс замены сменной компоненты в системе, в то время как система выполняет свою нормальную функцию, и при котором требуется человеческое вмешательство. (Сравните с AutoSwap и Cold Swap). Internal RAID Controller (Внутренний RAID Контроллер) - контроллер, который постоянно находится внутри компьютера или сервера и постоянно подключен к PCI шине. JBOD - Just A Bunch of Disks / Drives (Независимые Диски / Дисководы) - один или несколько дисководов, подключенные к RAID контроллеру, но не входящие в состав RAID массива и функционирующие независимо. Большинство RAID контроллеров поддерживают режим JBOD. Latency (Время ожидания) - 1. Время между посылкой запроса на выполнение операции ввода - вывода и началом выполнения операции. 2. Время между завершением процедуры поиска и моментом получения первого блока данных. M.O.R.E. - Mylex Online RAID Expansion - Технология фирмы Mylex, позволяющая "на лету" производить расширение RAID массива. Mirrored Cache (Зеркальный Кэш) - кэш-память, которая имеет копию данных от другого контроллера (в кластерных дисковых массивах). В случае отказа основного контроллера, второй контроллер может брать кэшированные данные и размещать их в дисковым массиве. Mirroring (Зеркалирование/Дублирование) - Технология полного дублирования данных, например, с одного дисковода на другой дисковод. Дублирование происходит при каждой операции чтения или записи. В результате, каждый дисковод является зеркальным отображением (дубликатом) другого дисковода. Этим же термином называют уровень RAID 1. Все RAID контроллеры поддерживают зеркалирование. MTBF - Mean Time Between Failures (Среднее Время Безотказной Работы) - Средняя наработка на отказ, среднее время от начала работы до первого отказа. MTDL - Mean Time until Data Loss (Среднее Время до Потери Данных) - среднее время от запуска до момента, пока отказ какой-либо составляющей дискового массива не будет вызывать постоянную потерю данных. PCI Hot Plug (Горячая Замена PCI Устройств) - свойство новейших персональных компьютеров с PCI шиной, позволяющее производить замену PCI карт без полного выключения системы. Queue (Очередь) - последовательность команд или данных, ожидающих обработки, обычно в порядке с начала последовательности. RAID - Redundant Array of Independent Disks (Избыточный Массив Независимых Дисков) - известно несколько различных форм выполнения RAID. Каждая форма именуется как " уровень RAID". Соответствующий уровень RAID для системы выбирается исходя из того параметра, который является основным: общий объем дисковой системы, отказоустойчивость или быстродействие. RAID Levels (Уровни RAID) - в настоящее время наиболее широко поддерживаются четыре основных уровня RAID (RAID 0, RAID 1, RAID 3, RAID 5) и два специальных уровня RAID (RAID 0+1, и JBOD). RAID Levels 0 (Уровень 0 или Striping): Блоки данных размещаются последовательно на нескольких дисководах, обеспечивая более высокую скорость доступа, чем при размещении на одном дисководе. Этот уровень не обеспечивает никакой избыточности. RAID Levels 1 (Уровень 1 или Mirroring): Дисководы объединены в пары и являются зеркальным отражением друг друга. Все данные на 100 процентов продублированы, но при этом занимают в два раза больше дискового пространства. RAID Levels 3 (Уровень 3): Данные "разбросаны" по нескольким физическим дисководам. Помимо данных на одном из дисководов хранится информация о четности, которая может использоваться для восстановления данных. RAID Levels 5 (Уровень 5): Данные "разбросаны" по нескольким физическим дисководам. Помимо данных на дисководах хранится информация о четности, которая может использоваться для восстановления данных. В отличие от RAID Levels 3 информация о четности распределена по всем дисководам для их равномерной загрузки. RAID Levels 0+1 (Уровень 0+1): Комбинация RAID 0 и RAID 1. Этот уровень обеспечивает избыточность за счет зеркалирования. RAID Levels JBOD (Уровень JBOD): сокращение от "Just a Bunch of Drives" (Только Связка Дисководов). Каждый дисковод используется независимо, как если бы они были подключены к обыкновенному контроллеру дисководов. Этот уровень не обеспечивает избыточность данных. RAID Levels 10 (Уровень 10): Комбинирует (объединяет) RAID 0 и RAID 1, т.е. зеркалирование группы дисководов, объединенных в RAID 0 для обеспечения максимального быстродействия. Этот уровень обеспечивает избыточность за счет зеркального отражения. RAID Levels 30 (Уровень 30): Комбинирует (объединяет) RAID 0 и RAID 3, т.е. используется контрольная сумма для группы дисководов, объединенных в RAID 0 для обеспечения максимального быстродействия. Информация о четности может использоваться для восстановления данных. RAID Levels 50 (Уровень 50): Комбинирует (объединяет) RAID 0 и RAID 5, т.е. используется перемещаемая контрольная сумма для группы дисководов, объединенных в RAID 0 для обеспечения максимального быстродействия. Информация о четности может использоваться для восстановления данных. RAID Migration (Перемещение RAID) - способность RAID контроллера производить изменение уровня RAID без выключения системы. Многие современные контроллеры поддерживают перемещение RAID. Recovery (Восстановление) - процесс восстановления данных от отказавшего дисковода, при котором используются данные от других дисководов. Redundancy (Избыточность) - включение в систему дополнительных однотипных компонентов, помимо необходимых для работы, для повышения надежности системы. Rotated XOR Redundancy (Распределенная Избыточность) - Этот термин относится к методу обеспечения полной избыточности данных при требовании максимально использовать емкость дисковой памяти. В системе, сконфигурированной под RAID 3 или RAID 5 (которые требуют, по крайней мере, три SCSI дисковода), все блоки данных и четности разделены между дисководами таким образом, что если один из дисководов будет удален (или даст сбой), то данные, находившиеся на нем могут быть восстановлены, используя данные и четности на оставшихся дисководах. В любом RAID 3 или RAID 5 массиве, объем дискового пространства, которая занимает распределенная избыточность, эквивалентна объему одного дисковода. SAF-TE - SCSI Accessed Fault-Tolerant Enclosure (Доступный через SCSI шину Отказоустойчивый Корпус) - "открытые" технические требования, разработанные для обеспечения всестороннего и стандартизированного метода контроля и вывода информации о состоянии дисководов, источников питания и систем охлаждения, используемых в серверах высокой надежности и подсистемах хранения данных. Технические требования независимы от аппаратного обеспечения ввода - вывода, операционных систем, платформ сервера, и выполнения RAID, потому что сам корпус представляется как просто еще одно устройство на SCSI шине. SAF-TE технические требования были приняты многими ведущими изготовителями серверов, устройств хранения данных и RAID контроллеров. Изделия, удовлетворяющие спецификации SAF-TE уменьшают стоимость затрат на контроль состояния корпусов, упрощают работу администратора сети, выдают аварийные уведомление и информацию о состоянии оборудования. SCA - Single Connector Attachment (Подключение через один разъем) - разновидность SCSI интерфейса, разработанного для обеспечения стандартного подключение винчестеров для систем, использующих технологию hot swap (горячая замена). Для подключения дисководов с SCA интерфейсом к SCSI шине используется специальная коммутационная плата, через которую на дисководы подается питание, обеспечиваются установки SCSI ID, и осуществляется терминация SCSI шины. SCSI Drive States (Состояния SCSI Дисковода) - относится к текущему состоянию SCSI дисковода. В любой момент времени, SCSI дисковод может быть в одном из пяти состояний: ГОТОВ, АКТИВИЗИРОВАН, ОЖИДАНИЕ, НЕРАБОЧИЙ, или ВОССТАНАВЛЕНИЕ. Контроллер SCSI хранит состояния о подключенных к нему SCSI дисководах в своей долговременной памяти. Эта информация сохраняется даже после с отключения питания. Следовательно, если SCSI дисковод был помечен как НЕРАБОЧИЙ в одном сеансе, он останется в НЕРАБОЧЕМ состоянии до тех пор, пока он не будет заменен или восстановлен, используя системную утилиту. Ниже приводится описания состояний: Ready (Готов): SCSI дисковод находится в состоянии "готов", если он включен и доступен, чтобы быть сконфигурированным в течение текущего сеанса, но остается не сконфигурированным. Online (Активизирован): SCSI дисковод находится в "активном" состоянии, если он включен, был определен как часть группы дисководов; и работает должным образом. Standby (Ожидание): SCSI дисковод находится в состоянии "ожидание", если он включен, способен работать должным образом, но не было определен, как часть какой-либо группы дисководов. Dead (Нерабочее): SCSI дисковод находится в "нерабочем" состоянии, если он не подключен к шине; или если он присутствует на шине, но на него не подано питание; или если он вышел из строя и был отключен контроллером. Когда контроллер обнаруживает отказ дисковода, он отключает этот дисковод, изменяя его состояние на "нерабочий". SCSI дисковод в состоянии "нерабочий" не участвует в каких-либо операциях ввода - вывода и никакие команды на него не передаются. Rebuild (Восстановление): SCSI дисковод находится в состоянии "восстановления" во время этого процесса. В течение этого процесса, данные восстанавливаются и записываются на дисковод. Это состояние также именуется состоянием 'Write-Only' (WRO) ("Только для записи"). Sector (Сектор) - минимальная единица объема хранения данных, в котором данные защищены от ошибок. Segment Size (Размер Сегмента) – параметр, задаваемый вместе с размером полосы (stripe size) и представляет собой размер данных, который будет прочитан или написан за одну операцию. Размер сегмента (также известный как "размер строки кэша") должен быть основан на размере полосы, который Вы выбрали. Обычно по умолчанию размер сегмента принимается равный 8КБайт. SMART - Self Monitoring Analysis and Reporting Technology (Технология Самоконтроля, Анализа и Сообщения) - промышленный стандарт предсказания надежности и для IDE/ATA и SCSI дисководов жестких дисков. Дисководы жестких дисков с функцией SMART позволяют заранее предупредить о возможном скором отказе жесткого диска, благодаря чему важные данные могут быть защищены. Standby Replacement of Disks ("Hot Spare") (Резервная Замена Дисководов ("Горячее резервирование")) - Одна из наиболее важных особенностей, которую обеспечивает RAID контроллер, с целью достичь безостановочное обслуживание с высокой степенью отказоустойчивости. В случае выхода из строя SCSI дисковода восстанавливающая операция будет выполнена RAID контроллером автоматически, если выполняются оба из следующих условий: 1) Имеется "резервный" SCSI дисковод идентичного объема, подключенный к тому же контроллеру; 2) Все системные дисководы и отказавший дисковод входят в состав избыточной дисковой системы, например RAID 1, RAID 3, RAID 5 или RAID 0+1. Обратите внимание: резервирование позволяет восстановить данные, находившиеся на неисправном дисководе, если все дисководы подключены к одному и тому же RAID контроллеру. "Резервный" дисковод может быть создан одним из двух способов: 1. Когда пользователь выполняет утилиту разметки, все дисководы, которые подключены к контроллеру, но не сконфигурированы в любую из групп дисководов, будут автоматически помечены как "резервные" дисководы. 2. Дисковод может также быть добавлен (подключен позднее) к работающей системе и помечен как резервный, при помощи соответствующей утилиты RAID контроллера для данной операционной системы. В течение процесса автоматического восстановления система продолжает нормально функционировать, однако производительность системы может слегка ухудшиться. Для того, что бы использовать восстанавливающую особенность резервирования, Вы должны всегда иметь резервный SCSI дисковод в вашей системе. В случае сбоя дисковода, резервный дисковод автоматически заменит неисправный дисковод, и данные будут восстановлены. После этого, системный администратор может отключить и удалить неисправный дисковод, заменить его новым дисководом и сделать этот новый дисковод резервным. Таблица резервных замен имеет предел 8 автоматических замен в любом сеансе (от момента включения питания/перезагрузки до следующего выключения питания/перезагрузки). Когда предел в 8 замен будет достигнут, и произойдет отказ дисковода, резервная замена произойдет, но она не будет зарегистрирована в таблице замен. Чтобы очистить таблицу резервных замен, перезагрузите систему от загрузочной DOS дискета, запустите утилиту конфигурации RAID контроллера и выберите опцию «Просмотреть / изменить конфигурацию» в главном меню. Выберете блок «Список Модификаций Дисковода». Вы должны сохранить конфигурацию без изменений и выйти из утилиты конфигурации. Это очистит таблицу замен. Вы можете теперь загрузить вашу систему и продолжить нормальные операции. Обычно предел таблицы замен на 8 событий не должен вызвать никаких проблем, так как при условии, что дисковые сбои происходят не чаще, чем один раз в год (а SCSI дисководы имеют 5-летную гарантию), система должна функционировать непрерывно как минимум 8 лет, прежде чем таблица замен должна будет очищена. Stripe Order (Порядок Полос) - порядок, в котором SCSI дисководы обслуживаются в пределах группы дисководов. Этот порядок должен соблюдаться, так как от этого зависит способность контроллера восстанавливать данные на вышедшем из строя дисководе. Stripe Size (Размер Полосы) - размер полосы определяется как размер, в килобайтах (1024 байта) одиночной операции ввода / вывода. Полоса данных разделена по всем дисководам в группе дисководов, при этом сами данные постоянно находятся в физических дисковых секторах, которые логически упорядочены с первого до последнего сектора. Stripe Width (Ширина Полосы) – количество разбитых на полосы SCSI дисководов в пределах группы дисководов. Striping Disk Drives (Разметка дисководов) – метод, позволяющий объединить несколько дисководов в RAID в один логический диск. Разметка включает в себя разбиение полезного объема каждого дисковода на полосы (страйпы – stripe), которые могут быть размером от одного сектора (512 байт), до нескольких мегабайт. Размер страйпов определяется исходя из типа программного обеспечения и интенсивности обмена данными. Затем эти страйпы вкруговую послойно объединяются, так что общий объем массива составлен из страйпов поочередно всех дисководов. Большинство современных операционных систем таких, как NT, UNIX, NetWare, поддерживают перекрытие (т.е. одновременное выполнение) операций ввода-вывода, совершаемых на разных дисководах. Следует иметь в виду, что для достижения максимальной скорости ввода-вывода необходимо равномерно распределить обращения к дисководам так, чтобы каждый дисковод работал максимально возможное время. В многодисковой системе без разметки равномерная загрузка дисководов практически невозможна. На некоторых дисководах будут находиться файлы, к которым обращения будут происходить часто, обращение же к файлам на других дисководах будет происходить лишь изредка. Оптимальная работа приложений с интенсивным вводом-выводом на дисковод достигается в том случае, когда размер страйпов достаточно велик, чтобы одна запись умещалась в одном страйпе. В этом случае можно быть уверенным, что данные и операции чтения-записи будут равномерно распределены между дисководами, входящими в состав массива. В этом случае каждый дисковод будет обслуживать свою операцию, что, в свою очередь, позволит довести количество одновременно выполняемых операций до максимума. В однопользовательской системе для приложений с интенсивным обменом и большим размером записей выгодно использовать небольшой размер страйпов. В этом случае скорость обмена возрастает вследствие того, что происходит одновременное считывание разных частей одной и той же записи с разных дисководов. К сожалению, небольшой размер записи практически полностью исключает одновременное выполнение разных операций чтения-записи, так как все дисководы участвуют в каждой операции. Это не страшно при работе в операционных системах типа DOS, так как такие операционные системы не «умеют» выполнять несколько одновременных обращений к дисководу. Видео- и аудио-приложения, а также медицинские приложения, работающие с длинными записями, будут работать в оптимальном режиме при небольшом размере страйпов массива. Потенциальным недостатком использования маленьких страйпов является то, что для достижения предельной скорости работы массива придется обеспечить синхронизацию вращения дисководов. Если этого не делать, то в каждый момент времени диски будут иметь разный угол поворота. А это значит, что операция чтения или записи не будет завершена до тех пор, пока все диски не повернуться в необходимое положение. В этом случае, чем больше дисководов в массиве, тем ближе среднее время завершения операции к наихудшему случаю – одиночного диска, находящегося в наиболее невыгодном положении. Синхронизация вращения дисков гарантирует, что все дисководы начнут и закончат чтение одновременно. В этом случае среднее время доступа массива в точности соответствует среднему времени доступа одиночного дисковода. Sustained Data Transfer Rate (Скорость Непрерывной Передачи Данных) - скорость передачи данных для непрерывной работы при максимальном быстродействии. Synchronous data transfer (Синхронная Передача Данных) - Передача данных, синхронизированная к определенному интервалу времени. Синхронная передача данных по SCSI шине происходит быстрее, чем асинхронная, потому что не требуется ожидания подтверждения получения каждого байта от приемного устройства. Target ID - Идентификатор SCSI устройства, подключенного к SCSI контроллеру. К каждому SCSI каналу контроллера может быть подключено до 15 SCSI устройств, каждое из которых должно иметь уникальный, отличный от других, идентификатор в диапазоне от 0 до 6, и от 8 до 15. Termination - метод согласования нагрузок полному волновому сопротивлению шины передачи данных, при котором устраняется отражения сигнала от физических концов шины. Transfer Rate (Скорость Передачи Данных) - скорость, с которой данные перемещаются между центральным процессором и памятью или устройствами ввода / вывода и обычно выражается в количестве передаваемых символов (байт) в секунду. Write Through Cache (Кэш со Сквозной Записью) - относится к стратегии кэширования, при которой данные пишутся в кэш и на SCSI дисковод прежде, чем состояние завершения будет возвращено ведущей операционной системе. Эта стратегия кэширования считается наиболее безопасной, так как при этом наименее вероятно, что сбой питания приведет к потере данных. Однако запись через кэш приводит к некоторому снижению производительности системы. Write-Back Cache (Кэш с Отложенной Записью) - относится к стратегии кэширования, при которой сигнал завершения операции записи посылается ведущей операционной системе, как только кэш (а не дисковод) принимает данные, которые должны быть записаны. На целевой SCSI дисковод эти данные запишутся только через некоторое время, но это почти не снизит производительность системы. Для защиты от потери данных в результате сбоя питания или аварийного отказа системы может использоваться специальная батарейка, поддерживающая питание микросхем кэша. | |
Категория: Статьи | Добавил: ipsyedinmk (11.11.2008)
| Автор: Максим  
| |
| Просмотров: 2091 |
| Всего комментариев: 0 | |

